Wiki Reader: 一个左右分栏的 EPUB + Wiki 阅读器
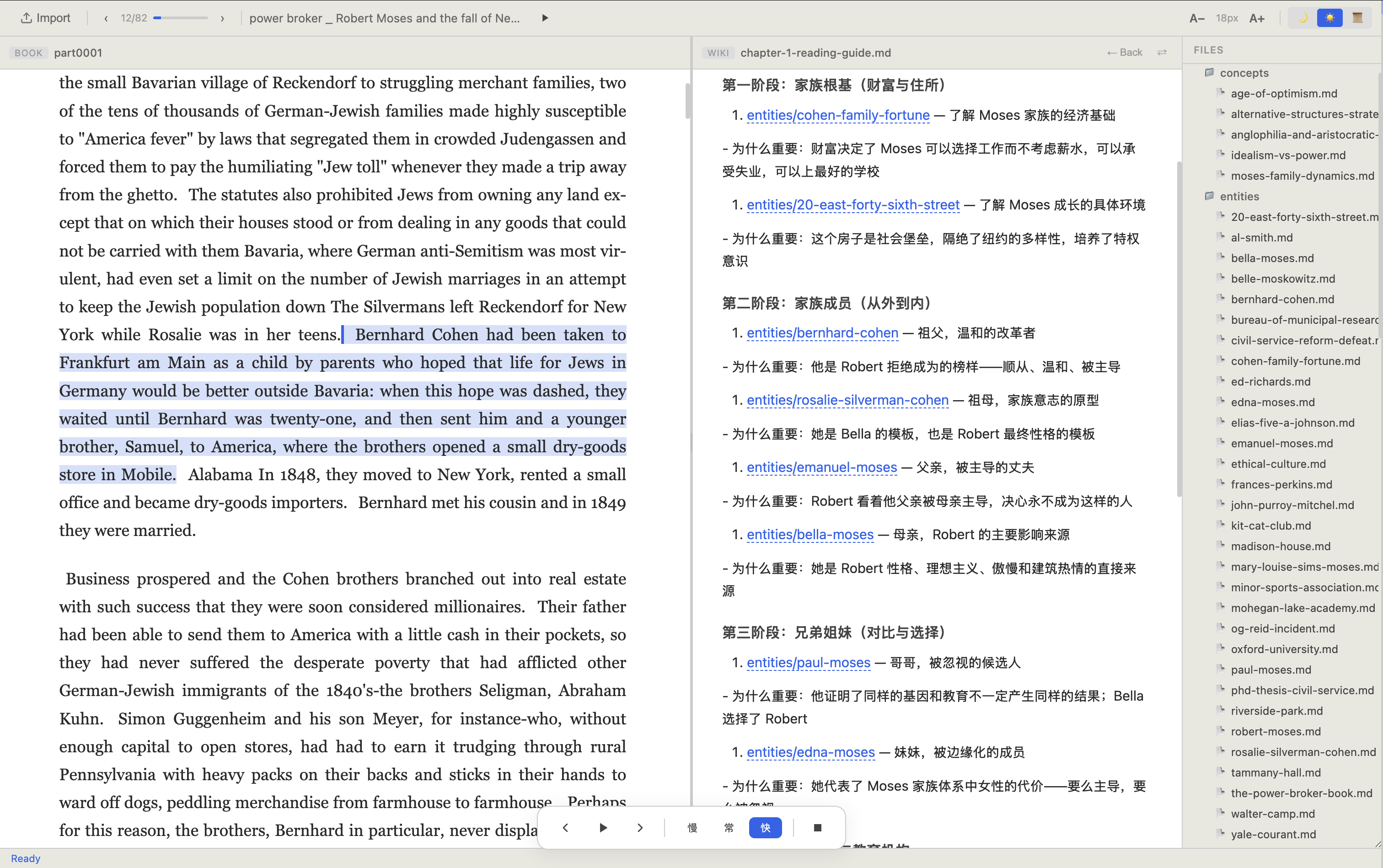
阅读非虚构类书籍时,我习惯先用 AI 整理成 Wiki——提取 entity 和 concept,形成结构化的笔记。但阅读时需要在书籍和笔记之间反复切换,多个应用来回跳转,注意力不断被打断。
于是 vibe 了一个阅读器:左侧 EPUB,右侧 Wiki,左右分栏对照阅读。
阅读时 Wiki 的预处理?
最近在看 Robert Caro 的 The Power Broker。完全不了解美国新政时期的政治背景,语言有隔阂,人物极度混乱——Robert Moses 的家人、同事、对手、机构,名字相似且关系复杂。直接硬读的话,读到头晕眼花也理不清头绪。
我的习惯是:先整理好人物和概念,把复杂的、揉成一团的信息,拆解成「元数据」(Entities)和「逻辑线」(Concepts)。经过这样的预处理,大脑才能通畅地输入信息。这是我自己阅读时的习惯,不是「偷懒」,只是分阶段处理——第一阶段用 AI 做信息拆解和结构化,第二阶段用人类的大脑做理解和整合。
LLM Wiki:预处理的工作流
我使用 LLM Wiki 这个 skill 来完成预处理。它基于 Andrej Karpathy 的 wiki 模式,核心思想是:把知识编译成相互链接的 markdown 文件网络,而不是每次查询都重新从原始材料中检索。
具体工作流分为三步:
- Ingest:把 EPUB 的每一章提取成 markdown,放入
raw/books/目录。这是不可变的原始材料。 - Extract:逐章分析,提取人物(Entities)和概念(Concepts),创建对应的 wiki 页面。每个人物一页,每个概念一页,页面之间用
[[wikilinks]]相互链接。 - Guide:为每一章创建阅读指南(Reading Guide),按照书中的叙述顺序排列实体页面,帮助读者按逻辑顺序阅读,而不是按字母顺序。
以 The Power Broker 第一章为例,阅读指南会引导你:先读 Cohen 家族财富和住所,再读家族成员(从外到内:Bernhard → Rosalie → Emanuel → Bella),然后是兄弟姐妹和价值观 institutions,最后才到核心人物 Robert Moses。这个顺序 mirrors 书中的叙事弧线,而不是 wiki 的字母顺序。
设计起点:为什么左右分栏?
Wiki 整理完成后,阅读时需要在书和笔记之间对照。传统的阅读流程是:读一段书,切到笔记应用查看相关概念,再切回书继续读。这个切换成本看似微小,但累积起来对阅读流畅性的破坏是实质性的。
左右分栏不是「同时看两边」,而是「需要时瞥一眼」。Wiki 面板默认显示文件树,点击后加载对应笔记。EPUB 阅读区保持独立滚动,Wiki 面板独立滚动,互不影响。
排版设计:为什么这样设定?
EPUB 阅读区使用 Georgia 衬线字体,18px 默认(可调 12-28px),行高 1.7,最大宽度 700px,两端对齐,自动断字。Wiki 面板使用系统无衬线字体栈,15px,行高 1.65。
衬线字体适合长文阅读,这是印刷传统的结论。Georgia 专为屏幕设计,衬线清晰但不夸张,小字号下仍有良好的可读性。无衬线字体适合 UI 和短文本,Wiki 面板以导航和检索为主,不需要长时间连续阅读。
行高 1.7 是研究共识的最佳值。过小导致行与行之间拥挤,视线容易串行;过大则破坏了段落作为视觉单元的整体性。最大宽度 700px 约 65-70 字符/行,符合 Bringhurst《The Elements of Typographic Style》的最佳行长研究——超过 80 字符/行,眼球水平移动距离增加,阅读疲劳显著上升;低于 40 字符/行,断行过于频繁,阅读节奏被打断。两端对齐配合自动断字(hyphens)提升阅读体验,避免右侧参差不齐造成的视觉跳动。
微交互:提供反馈,但不干扰
长时间阅读界面单调,但用户又不希望被干扰。需要在「提供反馈」和「保持专注」之间找到平衡。
基于 Frontiers in Psychology (2025) 元分析,注意力干扰对阅读理解有显著负面影响(Hedges' g = -0.64)。微交互应该「subtle yet noticeable」,不抢夺注意力。
仅采用两种微交互:段落 hover 高亮帮助定位,滚动进度指示提供空间定位感。悬浮在单个句子时,对该句子也有高亮,便于确认句子的边界,英语阅读时能辅助确定句子结构。拒绝打字机效果、持续动画等一切干扰性设计。
技术实现:为什么单文件?
整个应用是一个 HTML 文件(index.html),CSS 和 JS 全部内联。不依赖构建工具,不依赖服务器,浏览器直接打开即可运行。
EPUB 解析使用 JSZip(CDN 加载),解压后提取 HTML 章节。Wiki 使用浏览器 File System Access API 读取本地 Markdown 文件目录。书籍内容和 Wiki 文件通过 IndexedDB 持久化,刷新页面后自动恢复。
单文件架构的代价是代码组织不够优雅,但收益是零部署成本——用户不需要安装任何软件,不需要配置环境,不需要学习命令行。
TTS:句子级朗读
基于浏览器内置 SpeechSynthesis API,实现句子级朗读。点击句子开始朗读,当前句子高亮显示,读完自动推进到下一句。支持语速调节(0.75x / 1x / 1.5x),支持中英文自动切换。
不需要网络请求,不需要 API key,不需要后端服务。但受限于浏览器内置语音的质量,中文朗读尚可,英文朗读取决于系统安装的语音包。
使用场景
这个工具解决的是一个具体的问题:AI 辅助阅读非虚构类书籍时,减少上下文切换的摩擦。让书 and 笔记并排显示。
仓库地址:https://github.com/EisenJi/wiki-reader